Description
Motivation: A large number of services (such as wireless connectivity, location-based services, recommendations, etc.) rely on data and measurements collected from mobile devices and shared with a centralized entity. Users enjoy these services at the expense of sharing data from their mobile devices, which increases their privacy risk. For example, users may want to receive a location-based service, but they may be concerned about sending their exact location to a server or third parties.
Intellectual Merit: In this project, we consider data collected from mobile devices, including information about the wireless network, as well as personal/user data. Our goal is to develop privacy-preserving techniques to obfuscate reported data, while still providing guarantees for the quality of the provided service. We seek to develop both the theoretical frameworks (privacy-utility formulation, optimization of obfuscation techniques, principled data minimization), as well as its applications (to wireless spectrum sharing, cellular signal maps, and personal information tracking). The project will produce models, algorithms, datasets, mobile system implementations and programming interfaces, which trade off utility vs. privacy in a principled and transparent way. Here is the NSF Abstract.
Broader Impacts: The project involves collaborations with major players in the industries of wireless networks and crowdsourced data and has potential for technology transfer. The plan for Broadening Participation in Computing includes reaching out to women and undergraduates.
Team
Current members:
- PI: Athina Markopoulou, EECS Dept., UC Irvine
- Collaborative grant with Konstantinos Psounis, ECE Dept. USC
- Mengwei Yang, PhD student in EECS
- Yu Duan, PhD student in EECS
- Luca Baldesi, project scientist in EECS
Past Members:
- Tianyue Chu, visiting PhD student.
- Rahmadi Trimanada, postdoc, currently with Comcast Research.
- Evita Bakopoulou, PhD in Networked Systems, 2021; PhD Thesis on “Federated Learning for Mobile Data Privacy”; currently with Privacy Engineering at Google, Mountain View, CA.
- Emmanouil Alimpertis, PhD Thesis on “Mobile Coverage Signal Maps”, Networked Systems, UCI 2020; currently with Apple, Cupertino, CA.
- Anastasia Shuba, PhD Thesis on “Mobile Data Transparency and Control”, EECS, UCI 2019; currently with Broadcom, Los Angeles.
- Yanqi Gu, PhD student, Networked Systems.
- Justin Ley, undergrad in CS, MS in Math.
Publications (by topic)
Maverick-Aware Shapley Valuation for Client Selection in Federated Learning
Federated Learning (FL) allows clients to train a model collaboratively without sharing their private data. One key challenge in practical FL systems is data heterogeneity, particularly in handling clients with rare data, also referred to as Mavericks. These clients own one or more data classes exclusively, and the model performance becomes poor without their participation. Thus, utilizing Mavericks throughout training is crucial. In this paper, we first design a Maverick-aware Shapley valuation that fairly evaluates the contribution of Mavericks. The main idea is to compute the clients’ Shapley values (SV) class-wise, i.e., per label. Next, we propose FedMS, a Maverick-Shapley client selection mechanism for FL that intelligently selects the clients that contribute the most in each round, by employing our Maverick-aware SV-based contribution score. We show that, compared to an extensive list of baselines, FedMS achieves better model performance and fairer Shapley Rewards distribution.
- Mengwei Yang, Ismat Jarin, Baturalp Buyukates, Salman Avestimehr, Athina Markopoulou, “Maverick-Aware Shapley Valuation for Client Selection in Federated Learning”, poster in ISIT workshop on “Informational Theoretic methods for Trustworthy ML” (IT-TML), July 7th 2024, Athens, Greece.
PriPrune: Quantifying and Preserving Privacy in Pruned Federated Learning
Federated learning (FL) is a paradigm that allows several client devices and a server to collaboratively train a global model, by exchanging only model updates, without the devices sharing their local training data. These devices are often constrained in terms of communication and computation resources, and can further benefit from model pruning – a paradigm that is widely used to reduce the size and complexity of models. We perform the first investigation of privacy guarantees for model pruning in FL and derive information- theoretic upper bounds on the amount of information leaked by pruned FL models. Based on our evaluations, we introduce PriPrune– a privacy-aware algorithm for local model pruning, which uses a personalized per-client defense mask and adapts the defense pruning rate so as to jointly optimize privacy and model performance. PriPrune is universal in that can be applied after any pruned FL scheme on the client, without modification, and protects against any inversion attack by the server.
- Tianyue Chu, Mengwei Yang, Nikolaos Laoutaris, Athina Markopoulou. “PriPrune: Quantifying and Preserving Privacy in Pruned Federated Learning”, arXiv preprint arXiv:2310.19958 (2023), under review.
- Tianyue Chu, Mengwei Yang, Nikolaos Laoutaris, Athina Markopoulou, “Information-Theoretical Bounds on Privacy Leakage in Pruned Federated Learning”, poster and presentation, ISIT workshop on “Informational Theoretic methods for Trustworthy ML” (IT-TML), July 7th 2024, Athens, Greece.
Privacy by Projection: Federated Population Density Estimation by Projecting on Random Features.
We consider the problem of population density estimation based on location data crowdsourced from mobile devices, using kernel density estimation (KDE). In a conventional, centralized setting, KDE requires mobile users to upload their location data to a server, thus raising privacy concerns. Here, we propose a Federated KDE framework for estimating the user population density, which not only keeps location data on the devices but also provides probabilistic privacy guarantees against a malicious server that tries to infer users’ location. Our approach Federated random Fourier feature (RFF) KDE leverages a random feature representation of the KDE solution, in which each user’s information is irreversibly projected onto a small number of spatially delocalized basis functions, making precise localization impossible while still allowing population density estimation. We evaluate our method on both synthetic and real-world datasets, and we show that it achieves a better utility (estimation performance)-vs-privacy (distance between inferred and true locations) tradeoff, compared to state-of-the-art baselines (e.g., GeoInd). We also vary the number of basis functions per user, to further improve the privacy-utility trade-off, and we provide analytical bounds on localization as a function of areal unit size and kernel bandwidth.
- Zixiao Zong, Mengwei Yang, Justin Ley, Carter T. Butts, Athina Markopoulou, “Privacy by Projection: Federated Population Density Estimation by Projecting on Random Features“, to appear in Proceedings on Privacy Enhancing Technologies (PoPETs), 2023(1).
Mobile Signal Maps.
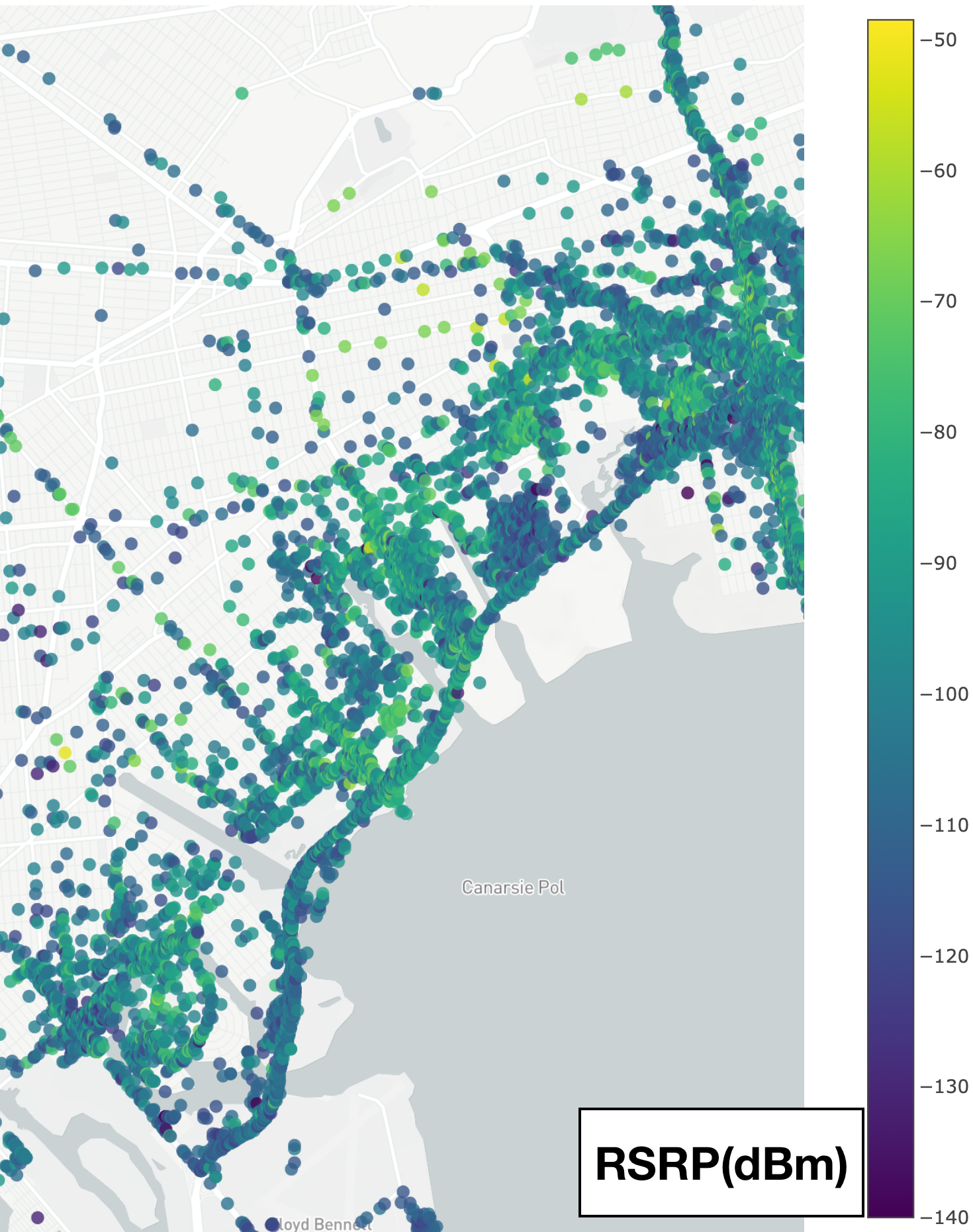
The first type of crowdsourced data we consider in this project are related to measurements of the quality of the cellular network itself. Mobile signal maps (for signal strength, coverage and other key performance indicators) are of great importance to cellular operators albeit expensive to obtain. Today, they are obtained primarily through crowdsourcing and third-party apps. Our earlier work focused on developing (i) tools for collecting and crowdsourcing network measurements from mobile devices and (ii) machine learning models, based on random forests and applied in a centralized way, to predict missing values. Our current work focuses on privacy-preserving techniques for crowdsourced mobile measurements, including federated learning (which is a natural fit for the decentralized crowdsourcing setting), secure aggregation, and data minimization.
- Evita Bakopoulou, Mengwei Yang, Jiang Zhang, Konstantinos Psounis, Athina Markopoulou, “Location Leakage in Federated Signal Maps”, accepted to IEEE Transactions in Mobile Computing, Oct. 2023. DOI: 10.1109/TMC.2023.3332034. [arxiv.org/abs/2112.03452]. [slides]
- E. Alimpertis, A. Markopoulou, C.T. Butts, E.Bakopoulou, K. Psounis, “A Unified Prediction Framework for Signal Maps”, accepted to IEEE Transactions on Mobile Computing, Oct. 2022; DOI: 10.1109/TMC.2022.3221773. [arxiv.org/abs/2202.03679].
- Emmanouil Alimpertis, PhD Thesis “Mobile Coverage Signal Maps”, UCI, June 2020.
- E. Alimpertis, A. Markopoulou, C. T. Butts, and K. Psounis, “City-Wide Signal Strength Maps: Prediction with Random Forests”, In Proc. of the ACM 2019 World Wide Web Conference (WWW ’19), May 13–17, 2019, San Francisco, CA, USA. [Proceedings, Poster Presentation]
Federated Mobile Packet Classification.
The second type of mobile data we study in this project are mobile packet traces collected from mobile devices. We develop techniques to predict whether these packets contain personally identifiable information (personal information “exposure”) or ad requests (which is then used for ad blocking), based on fields of the HTTP packet. Prior state-of-the-art classifiers were trained in a centralized way, while we applied for the first time federated learning to this problem.
- Evita Bakopoulou, Balint Tillman, Athina Markopoulou, “FedPacket: A Federated Learning Approach to Mobile Packet Classification“, in IEEE Transactions on Mobile Computing, February 2021. [Appendix]
- Evita Bakopoulou, Anastasia Shuba, Athina Markopoulou, “Exposures Exposed: A Measurement and User Study to Assess Mobile Data Privacy in Context”, in arxiv.org/abs/2008.08973 , August 2020.
- Evita Bakopoulou, Balint Tillman, Athina Markopoulou, “A Federated Learning Approach for Mobile Packet Classification”, in arxiv.org/abs/1907.13113, July 2019.
Extensions to Other End-Devices, Beyond Mobile
We also considered extensions and applications that consider data collection at a range of end-devices beyond just mobile devices. When possible, we observe activity at different levels: sensor data, network traffic, and commands exchanged between end-devices and the server. We also build classifiers, often across multiple network packts or sensor data. We report data collection practices and discuss their privacy implications
- Smarthome/IoT : PingPong: R. Trimananda, J. Varmarken, A. Markopoulou, B. Demsky, “Packet-Level Signatures for Smart Home Devices“, Proceedings of Network and Distributed System Security Symposium (NDSS) 2020. Feb. 2020, San Diego, CA. (acceptance rate ~18%) [slides] [dataset]
- VR Devices: BehaVR: Ismat Jarin, Yu Duan, Rahmadi Trimananda, Hao Cui, Salma Elmalaki, Athina Markopoulou BehaVR: User Identification Based on VR Sensor Data
Acknowledgements:
This work has been supported by the National Science Foundation under Grant No. 1900654: “CNS Core: Medium: Collaborative Research: Privacy-Preserving Mobile Crowdsourced Data”, Oct. 1st 2019 — Sept. 31st, 2023.
Disclaimer: Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.)
Point of Contact: please contact the PI, A. Markopoulou.
Last Updated: May. 10th, 2024